> ## Documentation Index
> Fetch the complete documentation index at: https://docs.cloosphere.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Arena · Leaderboard
> Objectively compare and rank model quality with Arena blind comparison and the Elo leaderboard
Admin › Evaluation › Arena · Leaderboard
**Arena · Leaderboard** pits two models against each other blindly (**Arena**) and ranks them by accumulating the results as an **Elo rating** (**Leaderboard**). It provides an objective comparison of model quality based on real users' choices.
***
## Arena
A feature for blind-evaluating two models by comparing their responses side by side.
### Setup
Admin › Evaluation › Arena
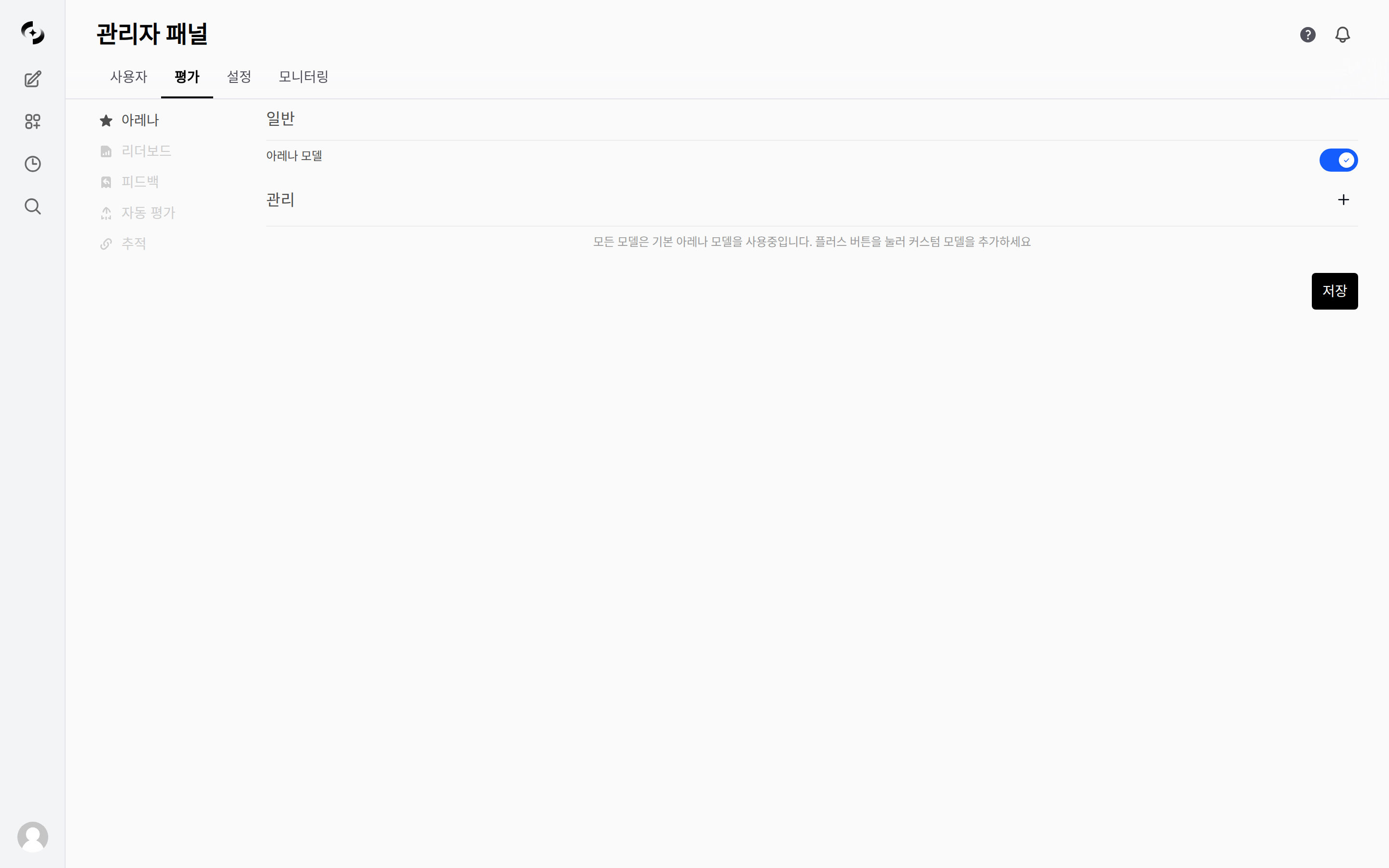 | Setting | Description |
| ---------------- | ----------------------------------------------------------------------------- |
| **Arena models** | Toggle whether Arena mode is used |
| **Manage** | Configure the models to compare (use default Arena models or add custom ones) |
Use **+** in the **Manage** item to add comparison models directly. Name and ID are required, and you specify access permissions and the models to include. Leaving the models empty includes all models.
| Setting | Description |
| ---------------- | ----------------------------------------------------------------------------- |
| **Arena models** | Toggle whether Arena mode is used |
| **Manage** | Configure the models to compare (use default Arena models or add custom ones) |
Use **+** in the **Manage** item to add comparison models directly. Name and ID are required, and you specify access permissions and the models to include. Leaving the models empty includes all models.
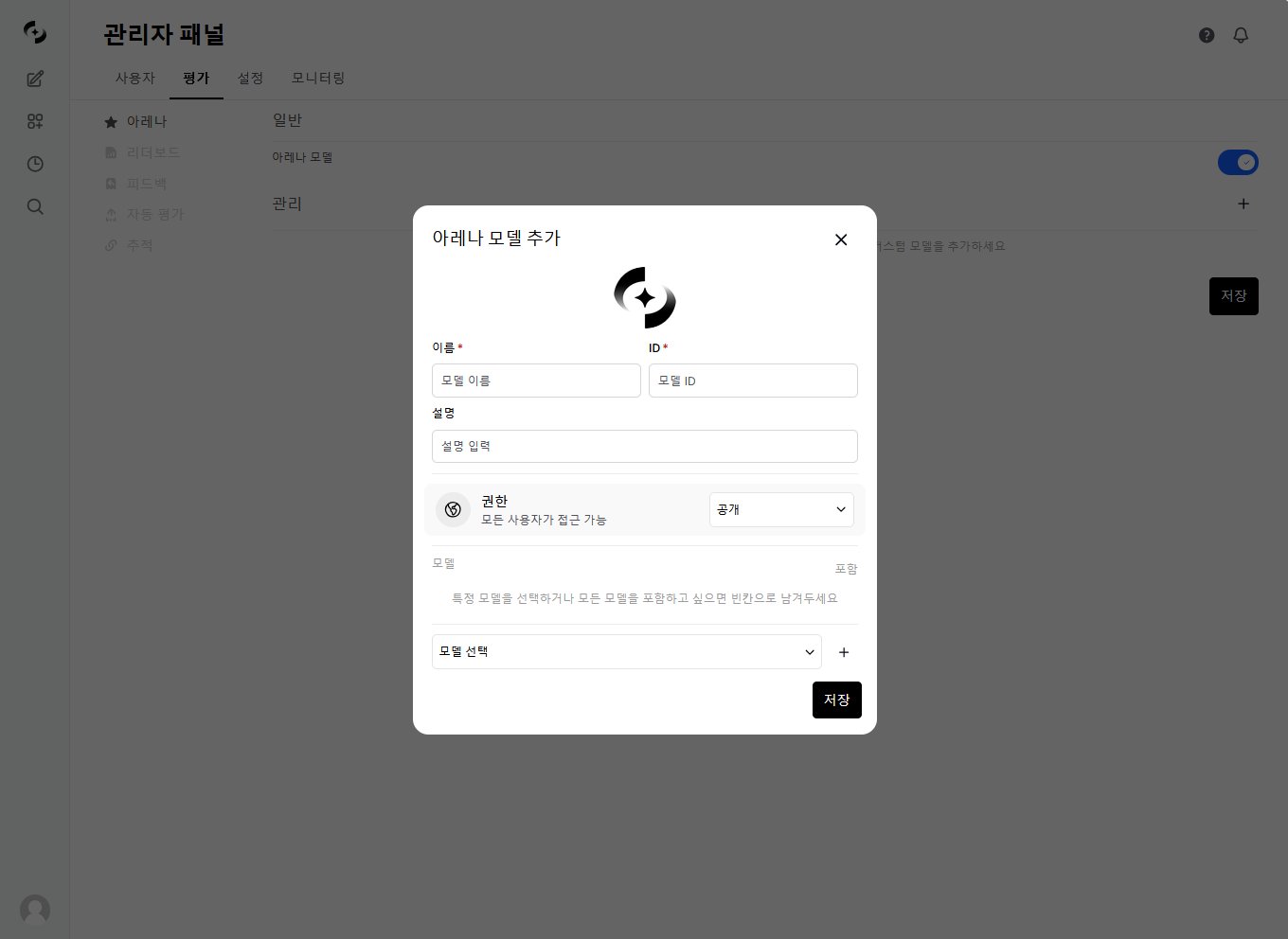 When Arena is enabled, two models' responses appear anonymously side by side while a user chats, and the user selects the better response.
***
## Leaderboard
Admin › Evaluation › Leaderboard
Calculates **Elo rating**-based model rankings from Arena blind comparison results.
Each time a user picks the better response in Arena, that model's Elo score updates, letting you objectively gauge real-usage-based model quality rankings.
When Arena is enabled, two models' responses appear anonymously side by side while a user chats, and the user selects the better response.
***
## Leaderboard
Admin › Evaluation › Leaderboard
Calculates **Elo rating**-based model rankings from Arena blind comparison results.
Each time a user picks the better response in Arena, that model's Elo score updates, letting you objectively gauge real-usage-based model quality rankings.
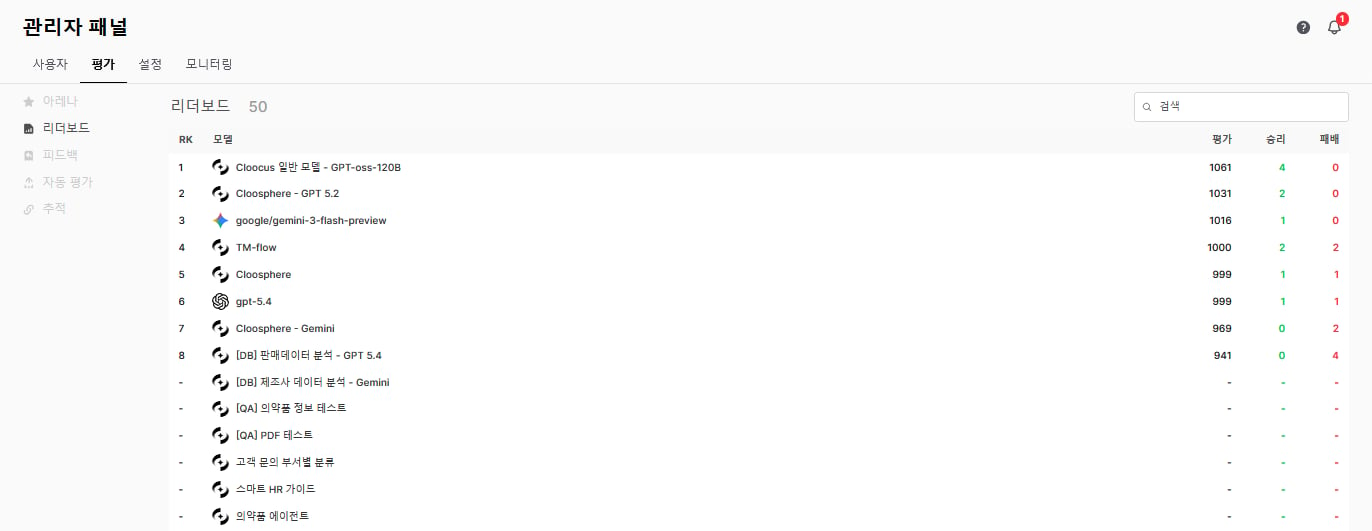 You can search rankings by model name in the search box at the top.
| Column | Description |
| -------------- | -------------------------------------------------------- |
| **RK** | Rank (descending by evaluation score) |
| **Model** | Evaluated model |
| **Evaluation** | Score derived from Arena comparison results (Elo rating) |
| **Wins** | Number of wins in Arena comparisons |
| **Losses** | Number of losses in Arena comparisons |
Example: RK 1 · Cloocus general model - GPT-oss-120B · Evaluation 1061 · Wins 4 · Losses 0
The leaderboard is in beta, and evaluation criteria may change as the algorithm is revised. It updates in real time based on the Elo evaluation system.
***
## Use Cases
1. Enable Arena evaluation to collect blind comparison data
2. Compare average scores in the per-model statistics of auto-evaluation
3. Set the model with the best cost-to-quality efficiency as the default model
***
## Related Pages
Full overview and guide to evaluation methods
Automatic quality scoring by a judge LLM
Check token usage per model
You can search rankings by model name in the search box at the top.
| Column | Description |
| -------------- | -------------------------------------------------------- |
| **RK** | Rank (descending by evaluation score) |
| **Model** | Evaluated model |
| **Evaluation** | Score derived from Arena comparison results (Elo rating) |
| **Wins** | Number of wins in Arena comparisons |
| **Losses** | Number of losses in Arena comparisons |
Example: RK 1 · Cloocus general model - GPT-oss-120B · Evaluation 1061 · Wins 4 · Losses 0
The leaderboard is in beta, and evaluation criteria may change as the algorithm is revised. It updates in real time based on the Elo evaluation system.
***
## Use Cases
1. Enable Arena evaluation to collect blind comparison data
2. Compare average scores in the per-model statistics of auto-evaluation
3. Set the model with the best cost-to-quality efficiency as the default model
***
## Related Pages
Full overview and guide to evaluation methods
Automatic quality scoring by a judge LLM
Check token usage per model