예시
“부서별 이번 분기 매출 비교해줘”
워크스페이스 > 데이터베이스에서 연결된 DB 목록을 확인합니다
NL-to-SQL 파이프라인
지원 데이터베이스
기본적으로 10종의 데이터베이스를 지원합니다.10종은 기본 활성화 상태입니다. 관리자가
DBSPHERE_TYPES 환경 변수로 노출 목록을 좁히거나 넓힐 수 있습니다.데이터베이스 연결
1
새 연결 생성
워크스페이스 > 데이터베이스 > ”+ 새 데이터베이스” 클릭 후 기본 정보를 입력합니다.
이름, 설명, 권한을 입력합니다
2
접속 정보 입력
DB Information에서 구성 버튼을 클릭하여 데이터베이스 접속에 필요한 정보를 입력합니다. 데이터베이스 유형에 따라 입력 정보가 달라집니다.공통 필드:
DB 유형별 추가 필드
DB 유형별 추가 필드
공통 필드(호스트·포트·데이터베이스·사용자 이름·비밀번호·쿼리 최대 실행시간) 외에 DB 유형별로 아래 필드가 추가됩니다.
3
연결 테스트
“연결 테스트” 버튼을 클릭하여 접속을 확인합니다.
4
테이블 선택
연결 성공 후 AI가 참조할 테이블을 선택합니다.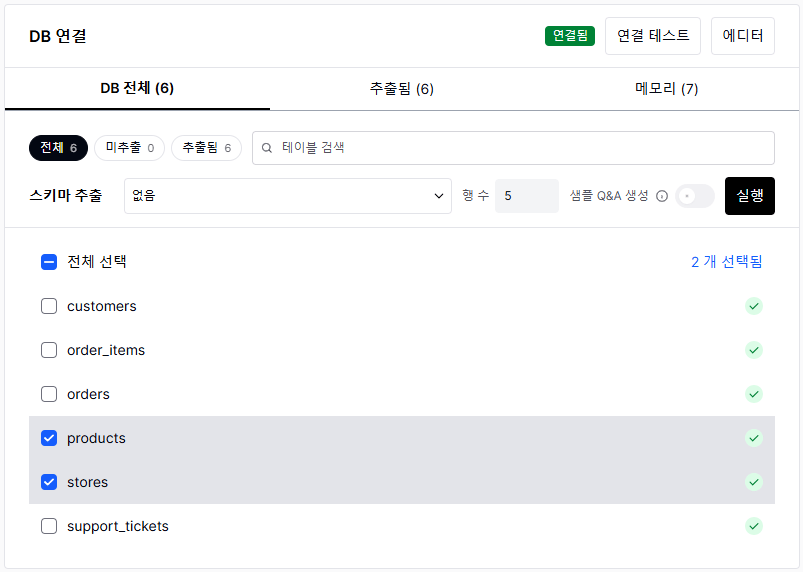
AI가 참조할 테이블만 선택합니다 — 민감 데이터 테이블은 반드시 제외하세요
5
도구 설명 설정 (선택)
에이전트가 이 데이터베이스를 언제, 어떻게 활용할지 안내하는 도구 설명을 작성합니다.AI 자동 생성: 도구 설명 입력란 옆의 자동 생성 버튼을 클릭하면, 연결된 테이블 구조와 컬럼 정보를 분석하여 AI가 도구 설명을 자동 작성합니다.
도구 설명 예시
도구 설명 예시
6
접근 권한 설정
상단의 자물쇠 모양 버튼을 눌러 데이터베이스의 접근 권한을 설정합니다.
AI가 SQL을 생성하는 흐름
에이전트에 DB를 연결하면, 사용자 질문이 다음 과정을 거쳐 SQL로 변환됩니다.성공한 쿼리가 자동으로 메모리에 누적됩니다. 사용할수록 AI가 비슷한 질문에 더 정확한 SQL을 생성하게 됩니다.
메모리 시스템
DbSphere는 4종류의 메모리를 활용하여 SQL 생성 정확도를 높입니다. 메모리가 많을수록 AI가 더 정확한 쿼리를 작성합니다.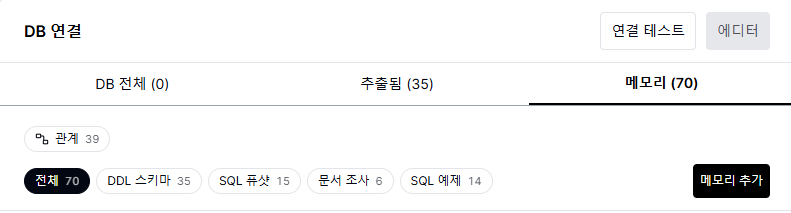
메모리 탭에서 4종 메모리를 확인하고 관리할 수 있습니다
DDL 스키마 설명으로 정확도 높이기
DDL 스키마 메모리의 테이블·컬럼에 비즈니스 설명을 추가하면 AI의 SQL 생성 정확도가 크게 향상됩니다. 스키마 추출 후 메모리 탭 → DDL 스키마 클릭 → 편집에서 각 테이블과 컬럼에 한국어 설명을 입력합니다.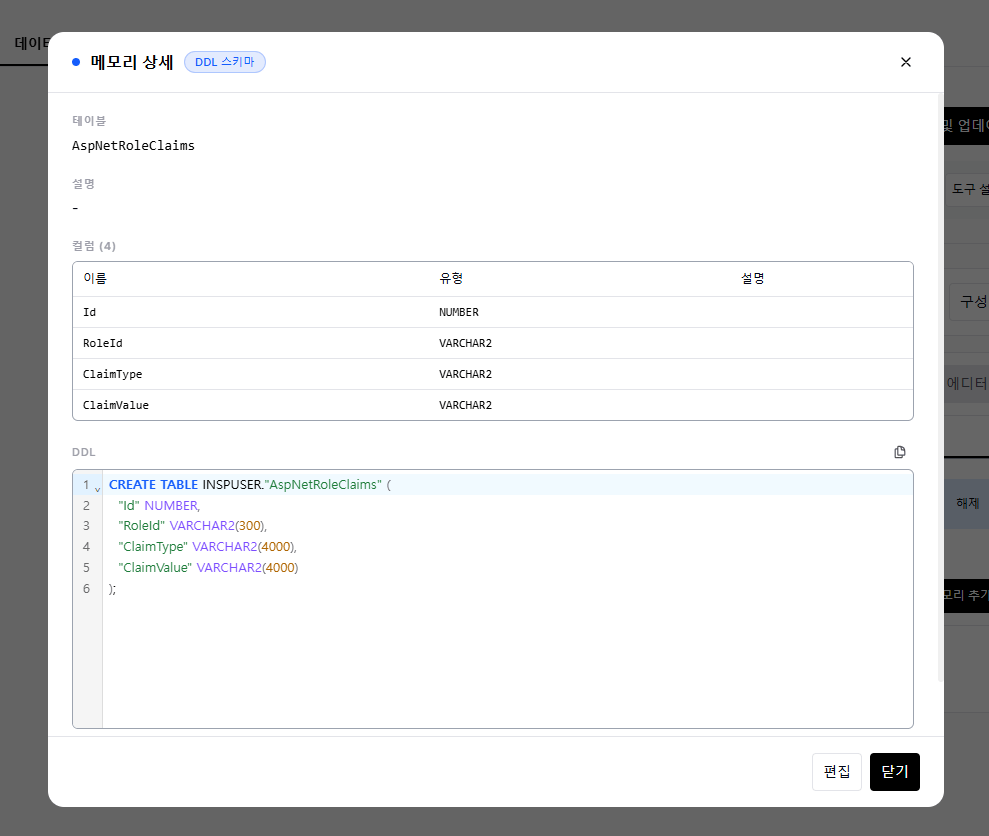
메모리 탭 → DDL 스키마 → 편집에서 테이블·컬럼 설명을 입력합니다
스키마 설명 예시
스키마 설명 예시
SQL 퓨샷이 핵심
SQL 퓨샷은 성공한 쿼리가 자동으로 저장되는 few-shot learning 메모리입니다.문서 조사 활용
AI가 모르는 비즈니스 규칙을 문서로 알려줄 수 있습니다.데이터 시각화
SQL 실행 결과는 기본적으로 표로 제공됩니다. “차트로 보여줘”처럼 요청하면 데이터에 맞는 차트로 시각화하고, 결과 상단의 차트 타입 토글로 직접 전환할 수 있습니다.
차트로 요청하면 데이터 구조에 맞는 차트 타입을 추천·자동 선택하며, 상단 토글에서 다른 타입으로 변경할 수 있습니다.
데이터베이스 조회
에이전트에 연결
- 에이전트 편집 화면에서 “데이터베이스” 섹션의 “데이터베이스 선택” 클릭
- 연결할 데이터베이스 선택
- 적용 클릭
채팅에서 사용
데이터베이스가 연결된 에이전트와 대화하면, AI가 질문을 분석하여 자동으로 SQL을 생성하고 실행합니다.질문 예시
- 매출 분석
- 고객 분석
- 재고 관리
- 인사 관리
SQL 실행 결과 확인
AI 응답 하단에 “SQL Query” 버튼이 표시됩니다. 클릭하면 실제 실행된 SQL과 결과를 상세하게 확인할 수 있습니다.결과 데이터는 최대 100행까지 표시됩니다. 전체 행 수가 100행을 초과하면 “Showing 100 of N rows” 안내가 표시됩니다. 전체 데이터가 필요하면 **채팅 결과 표 우측 상단의
CSV로 내보내기**로 내려받으세요.DB 문법 차이
각 DB는 SQL 문법이 조금씩 다릅니다. Cloosphere는 자연어 → SQL 변환 시 DB별 문법 규칙을 시스템 프롬프트에 동적으로 주입해 AI가 올바른 SQL을 생성하도록 유도합니다. 다만 다음 항목은 사용자가 의도를 명확히 표현하면 더 정확한 SQL이 생성됩니다.핵심 차이 비교
시스템 자동 보정 vs 사용자 책임
자동으로 처리되는 것:- 대시보드 기간 필터(
$st/$ed플레이스홀더): DB별 날짜 리터럴로 자동 변환 - 지식 그래프 값 추출 시 식별자 인용: DB별 따옴표 자동 선택
- AI에 전달되는 시스템 프롬프트에 DB별 문법 규칙 동적 주입 (LIMIT, 날짜, 식별자 등)
- 자연어 쿼리에 한글·특수문자 컬럼명을 직접 적을 때 — AI가 따옴표를 누락하면 실패할 수 있음
- Oracle 빈 문자열 비교 (아래 Oracle 특이점 섹션 참조)
- 복잡한 윈도우 함수·CTE 같은 고급 SQL은 DB별 지원 차이가 있어 AI 생성 결과 검증 필요
Oracle DB 특이점
Oracle은 ANSI SQL과 일부 동작이 달라 사용자가 알아둘 만한 항목이 있습니다.빈 문자열은 NULL로 처리됩니다 ⚠️
빈 문자열은 NULL로 처리됩니다 ⚠️
Oracle은 올바른 사용:Cloosphere의 시스템 프롬프트에 이 규칙이 포함되어 있어 AI가 자동으로 회피하지만, 자연어 쿼리에서 “비어있지 않은 항목” 같은 모호한 표현 사용 시 0행이 반환되면 이 패턴을 의심하세요.
''(빈 문자열)을 NULL과 동일하게 취급합니다. 따라서 다음 같은 조건은 항상 0행을 반환합니다:날짜 리터럴은 TO_DATE() 사용
날짜 리터럴은 TO_DATE() 사용
다른 DB와 달리 Oracle은 문자열을 자동으로 날짜로 캐스팅하지 않습니다.BI 대시보드의 기간 필터(
$st/$ed)는 Oracle 사용 시 자동으로 TO_DATE(...) 형태로 치환됩니다. 그러나 SQL 결과 화면에서 직접 SQL을 작성할 때는 사용자가 명시해야 합니다.날짜 산술은 INTERVAL 대신 직접 가감
날짜 산술은 INTERVAL 대신 직접 가감
DATE_TRUNC() 대신 TRUNC(col, 'DD'), 요일 추출은 EXTRACT(DOW FROM col) 대신 TO_CHAR(col, 'D')를 사용합니다.한글·특수문자 컬럼명 인용
한글·특수문자 컬럼명 인용
Oracle에서 한글 컬럼 별칭(이 규칙은 시스템 프롬프트에 포함되어 AI가 따옴표를 자동으로 적용하지만, 한글 컬럼이 많은 환경에서는 결과를 확인하고 누락 시 직접 수정하세요.
AS 공장코드)을 그대로 쓰면 ORA-00936: missing expression 오류가 발생합니다.LIMIT 대신 FETCH FIRST
LIMIT 대신 FETCH FIRST
보안
읽기 전용
DbSphere는 SELECT 쿼리만 실행합니다. 데이터 변경은 불가능합니다.자격 증명 보호
- 데이터베이스 비밀번호는 암호화하여 저장합니다
- 연결 정보는 접근 권한이 있는 사용자만 확인할 수 있습니다
베스트 프랙티스
데이터베이스 계정 설정
- 전용 계정 생성: AI 전용 읽기 전용 계정을 만드세요
- 최소 권한 부여: 필요한 테이블에 대해서만 SELECT 권한을 부여하세요
- 쿼리 제한: 타임아웃과 결과 행 수 제한을 설정하세요
테이블 선택
- 필요한 것만 선택: 모든 테이블을 연결하면 AI가 혼란스러워질 수 있습니다
- 민감 데이터 제외: 개인정보, 비밀번호가 포함된 테이블은 반드시 제외하세요
- 관련 테이블 함께 선택: JOIN이 필요한 테이블은 함께 선택하세요
스키마 설명 작성
- 한국어 설명 권장: 업무 용어를 사용하여 테이블과 컬럼을 설명하세요
- 비즈니스 컨텍스트 추가: “status” 컬럼의 가능한 값과 의미를 기술하세요
- 테이블 관계 명시: 외래 키 관계와 JOIN 조건을 설명하세요
트러블슈팅
연결 테스트가 실패합니다
연결 테스트가 실패합니다
AI가 잘못된 SQL을 생성합니다
AI가 잘못된 SQL을 생성합니다
응답이 느립니다
응답이 느립니다
FAQ
데이터가 변경될 수 있나요?
데이터가 변경될 수 있나요?
아니요, DbSphere는 읽기 전용입니다. SELECT 쿼리만 실행하며, 데이터를 수정하거나 삭제할 수 없습니다. SQL 첫 단어가
SELECT가 아니면 즉시 차단됩니다.실행된 SQL을 볼 수 있나요?
실행된 SQL을 볼 수 있나요?
네, AI 응답에서 생성된 SQL을 확인할 수 있습니다. 추적에서도 실행된 SQL과 결과를 상세하게 확인할 수 있습니다.
여러 테이블을 JOIN할 수 있나요?
여러 테이블을 JOIN할 수 있나요?
네, 관련 테이블을 모두 선택하고 테이블 간 관계를 스키마 설명에 기술하면 AI가 적절한 JOIN 쿼리를 생성합니다.
한 에이전트에 여러 데이터베이스를 연결할 수 있나요?
한 에이전트에 여러 데이터베이스를 연결할 수 있나요?
네, 에이전트에 여러 데이터베이스를 연결하면 AI가 질문에 따라 적절한 데이터베이스를 자동으로 선택합니다. 이때 각 DB의 도구 설명을 구체적으로 작성하면 선택 정확도가 높아집니다.
스키마 추출 시 모델을 선택하면 뭐가 달라지나요?
스키마 추출 시 모델을 선택하면 뭐가 달라지나요?
모델을 선택하면 LLM이 테이블/컬럼에 비즈니스 설명을 자동 생성하고, 샘플 Q&A 쌍도 만들어줍니다. 모델 없이 추출하면 DDL 구조만 저장됩니다. 모델 선택을 권장합니다.
관련 페이지
에이전트
DB를 에이전트에 연결하여 자연어 질의 활성화
용어집
DB 비즈니스 용어를 AI에게 알려주어 정확도 향상
추적
SQL 생성·실행 과정을 단계별로 추적