관리자 › 평가 › 자동 평가
자동 평가는 라이선스 기능입니다.
evaluation 피처가 활성화된 라이선스가 필요합니다.평가 유형
| 유형 | 설명 |
|---|---|
| 검색 품질 (Retrieval Quality) | 검색된 문서가 질문과 관련성이 있는지 평가 |
| 충실성 (Faithfulness) | 검색 내용에 기반한 답변인지 평가 (환각 감지) |
| 응답 품질 (Response Quality) | 전반적인 유용성과 정확성 평가 |
평가 프로세스
자동 평가 켜기 (에이전트에서 활성화)
자동 평가는 에이전트 단위로 활성화합니다. 켜야 결과가 쌓이기 시작합니다.자동 평가 활성화
에이전트 설정의 자동 평가 섹션에서 활성화합니다.
샘플링 비율 권장:
| 설정 | 설명 |
|---|---|
| 활성화 | 자동 평가 사용 여부 |
| 샘플링 비율 | 평가할 응답 비율 (1%~100%, 기본 10%) |
| 심판 모델 | 평가에 사용할 LLM 모델 |
| 평가 유형 | 활성화할 평가 유형 선택 |
| 상황 | 권장 | 이유 |
|---|---|---|
| 신규 에이전트 | 50~100% | 초기 품질 빠르게 파악 |
| 안정화 후 | 5~10% | 비용 절감 + 모니터링 |
| 핵심 업무 | 20~30% | 품질 보증 |
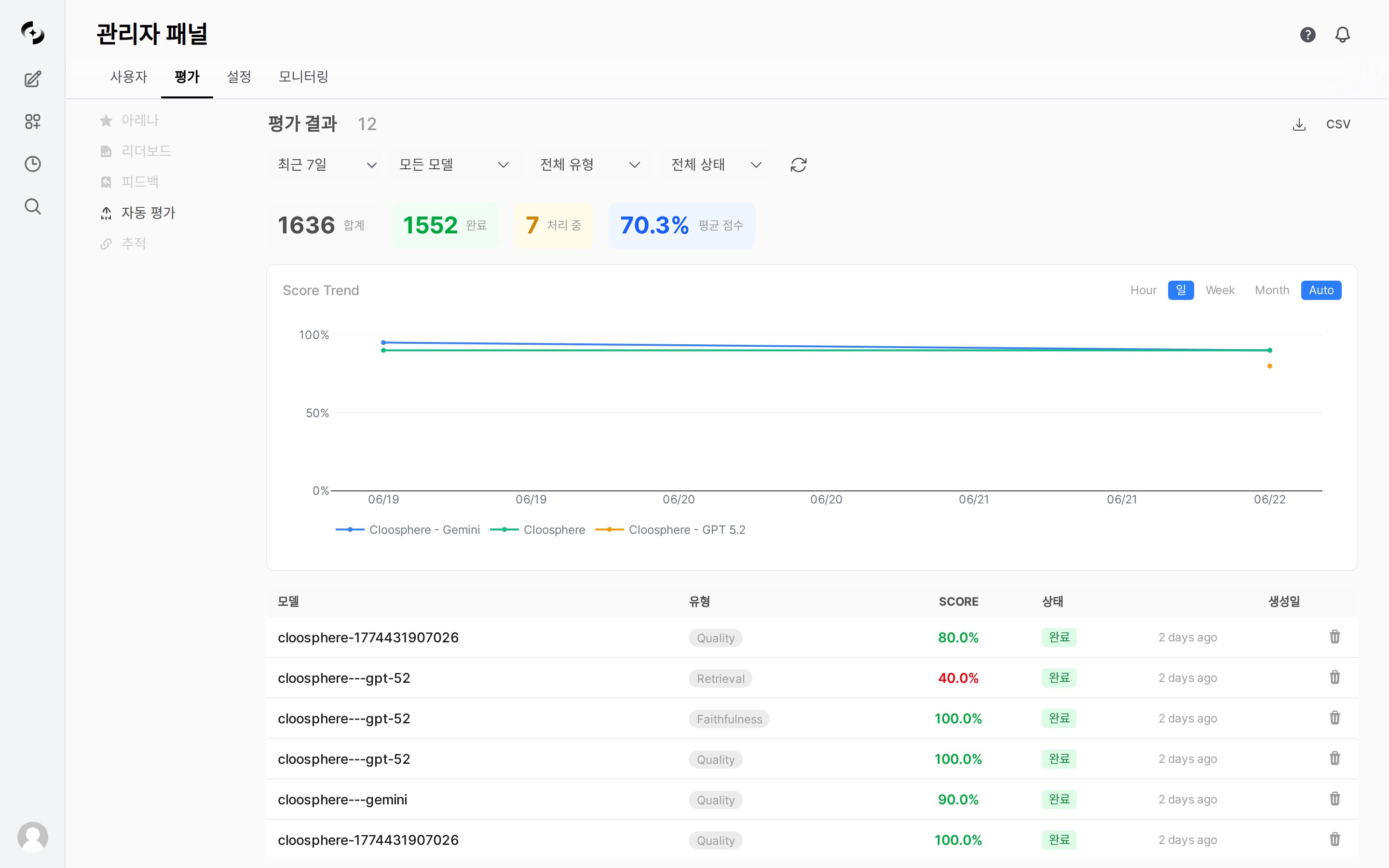
평가 결과 필드
| 필드 | 설명 |
|---|---|
| 채팅/메시지 ID | 평가 대상 메시지 |
| 모델 ID | 응답을 생성한 모델 |
| 심판 모델 ID | 평가에 사용된 LLM |
| 평가 유형 | retrieval, faithfulness, quality |
| 점수 | 0.0 ~ 1.0 (1.0이 최고) |
| 근거 | 점수에 대한 LLM의 설명 |
| 상태 | pending, completed, failed |
| 에러 메시지 | 평가 실패 시 오류 내용 |
Score Trend 차트
날짜별 평균 점수 추이를 시각화합니다.| 모드 | 설명 |
|---|---|
| 모든 유형 | 모델별 평균 점수 라인 |
| 특정 유형 선택 | 모델 + 유형별 세분화 라인 |
필터 옵션
| 필터 | 설명 |
|---|---|
| 날짜 범위 | 평가 기간 선택 |
| 모델 | 특정 모델로 필터 |
| 평가 유형 | 검색 품질, 충실성, 응답 품질 |
| 상태 | pending, completed, failed |
| 점수 범위 | 최소/최대 점수 (0.0 ~ 1.0) |
자동 평가 통계
전체 자동 평가의 요약 통계를 제공합니다.| 지표 | 설명 |
|---|---|
| 전체 건수 | 총 자동 평가 수 |
| 완료 | 성공적으로 완료된 평가 수 |
| 대기 | 아직 처리 중인 평가 수 |
| 실패 | 오류로 실패한 평가 수 |
| 평균 점수 | 전체 평균 점수 |
| 모델별 통계 | 모델별 건수 및 평균 점수 |
| 유형별 통계 | 평가 유형별 건수 및 평균 점수 |
내보내기
자동 평가 데이터를 내보낼 수 있습니다.| 형식 | 설명 |
|---|---|
| CSV | 스프레드시트 분석용 (id, chat_id, message_id, model_id, score, reasoning 등) |
| JSON | 프로그래밍 연동용 전체 데이터 |
활용 사례
응답 품질 모니터링
응답 품질 모니터링
- Score Trend 차트에서 일간/주간 점수 추이를 확인합니다
- 특정 모델의 점수가 하락하면 해당 기간의 트레이스를 확인합니다
- 낮은 점수의 개별 평가를 클릭하여 reasoning(근거)을 확인합니다
- 프롬프트, 지식기반, 도구 설정을 조정합니다
문제 해결
자동 평가가 실패(failed)하면?
자동 평가가 실패(failed)하면?
자동 평가가 failed 상태인 경우:
- 에러 메시지 확인: 결과 테이블에서 해당 항목의 에러 내용 확인
- 일반적인 원인: 심판 모델의 API 오류, 타임아웃, 토큰 한도 초과
- 재실행: 현재 자동 재실행은 지원되지 않습니다. 에이전트 설정에서 자동 평가를 재활성화하면 이후 응답부터 다시 평가됩니다.
관련 페이지
평가
수동 피드백·아레나·리더보드 등 평가 전체 개요
추적
낮은 평가 점수의 원인을 트레이스에서 추적
에이전트 설정
자동 평가를 에이전트에 설정