관리자 › 설정 › 문서
- 콘텐츠 추출 엔진, 텍스트 분할 방식, 임베딩 모델을 올바르게 구성해야 RAG 검색 정확도가 보장됩니다.
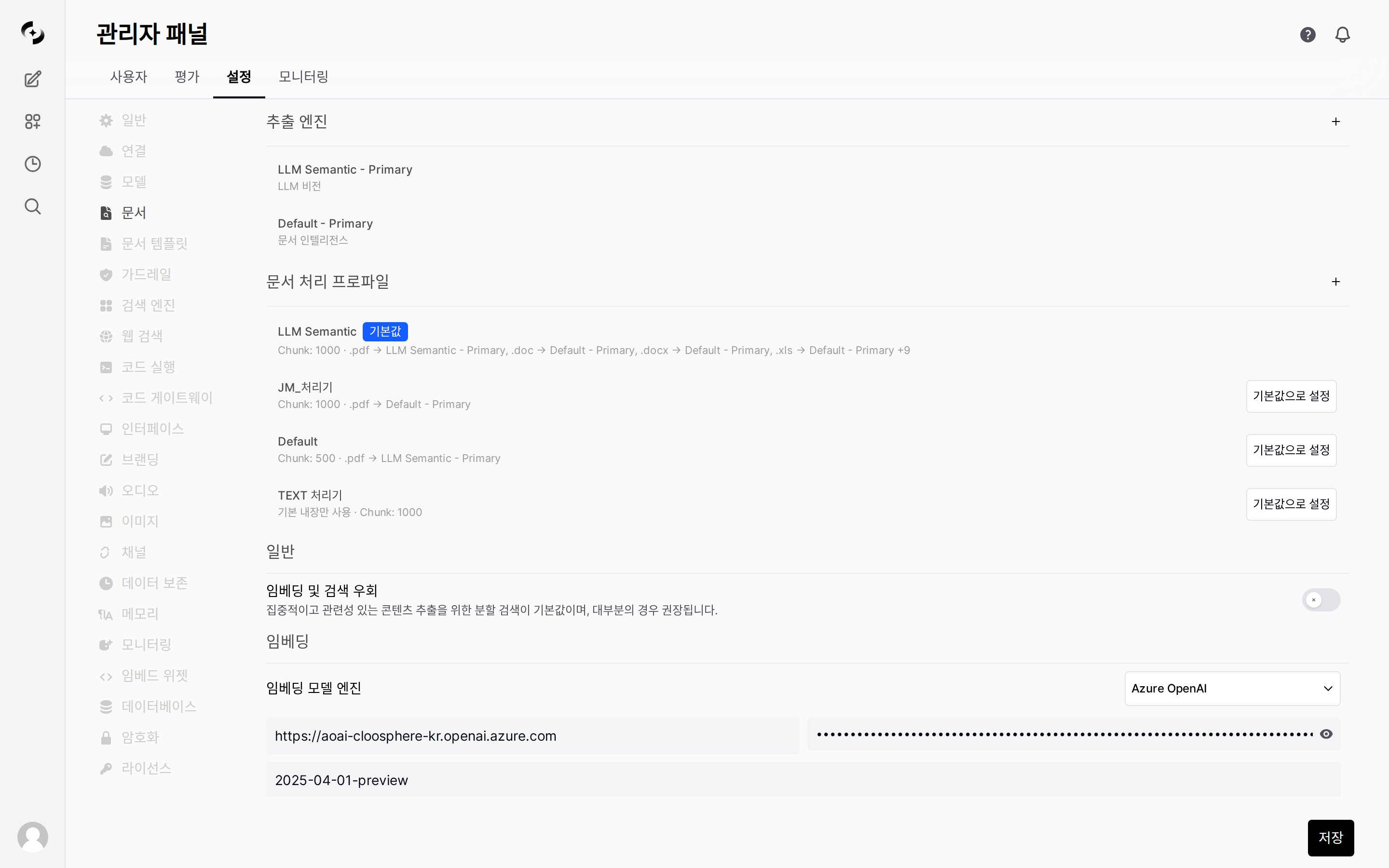
관리자 > 설정 > 문서에서 RAG 파이프라인의 모든 설정을 관리합니다
추출 엔진
페이지 상단의 추출 엔진 섹션에서 문서 텍스트 추출에 사용할 엔진 인스턴스를 등록·관리합니다.- 추출은 “엔진 하나를 전역으로 고르는” 방식이 아니라, 이름 붙은 인스턴스를 등록해 두고 프로파일에서 확장자별로 골라 쓰는 구조입니다.
1
엔진 인스턴스 등록
추출 엔진 섹션의 ”+” 버튼으로 인스턴스를 추가하고, 이름과 엔진 유형(Default, LLM 비전, Document Intelligence 등 — 유형별 설명은 콘텐츠 추출 참고)을 지정합니다. 같은 유형으로 설정이 다른 인스턴스를 여러 개 등록할 수 있습니다.
2
Primary 지정
인스턴스를 Primary로 지정합니다. 프로파일에서 특정 확장자를 개별 인스턴스에 매핑하지 않으면, Primary 인스턴스가 기본 추출기로 사용됩니다.
등록된 인스턴스는
이름 - Primary 형태로 표시되며(예: Default - Primary, LLM Semantic - Primary), 프로파일의 확장자 매핑에서 이 이름으로 참조됩니다.문서 처리 프로파일
신규 기능 — 문서 추출 방식과 청킹 전략을 묶어 프로파일로 관리할 수 있습니다. 여러 프로파일을 만들어두고 지식 기반(KB)별로 선택하여 사용합니다.
프로파일이란?
기존에는 전역으로 하나의 추출/청킹 설정만 가능했습니다. 프로파일을 사용하면 용도별로 서로 다른 설정 묶음을 정의하고, KB마다 적합한 프로파일을 선택할 수 있습니다. 각 프로파일은 파일 확장자별 추출 엔진 매핑(예:.pdf → Default - Primary)과 청킹 설정으로 구성됩니다.
프로파일 관리
문서 설정 페이지 상단의 문서 처리 프로파일 섹션에서 프로파일을 생성하고 관리합니다.1
프로파일 생성
+ 새 프로파일 버튼을 클릭하여 프로파일 생성 모달을 엽니다.
2
기본 프로파일 설정
프로파일 목록에서 기본값으로 설정 버튼을 클릭하면, 해당 프로파일의 설정이 전역 기본값으로 동기화됩니다. 프로파일을 지정하지 않은 KB는 이 기본 프로파일로 처리됩니다.
3
KB에서 프로파일 선택
워크스페이스 > 지식 기반 편집 화면에서 문서 처리 프로파일을 선택합니다. 미선택 시 기본 프로파일이 적용됩니다.
콘텐츠 추출
추출 엔진 인스턴스로 만들 수 있는 엔진 유형입니다.- 각 유형을 인스턴스로 등록한 뒤, 프로파일에서 확장자별로 매핑해 사용합니다.
LLM 비전 추출
신규 기능 — Vision을 지원하는 LLM(GPT-4o, Claude 등)에게 페이지 이미지를 직접 보내 마크다운 텍스트로 추출하는 방식입니다.
- PDF를 페이지별 이미지로 변환 (300DPI급)
- 각 페이지 이미지를 Vision LLM에 병렬 전송
- LLM이 표/리스트/제목 구조를 유지한 마크다운으로 반환
- 인접 페이지 경계의 끊긴 문장을 자동 보정
LLM 비전은 PyMuPDF 패키지가 필요합니다. 미설치 시 이 엔진을 선택한 문서 업로드가 실패합니다. 배포 환경에서 PyMuPDF 설치 여부를 확인하세요.
텍스트 분할
추출된 텍스트를 검색에 적합한 크기로 분할하는 방식을 설정합니다.Chunk Size를 어떻게 정해야 하나요?
Chunk Size를 어떻게 정해야 하나요?
Chunk Overlap은 왜 필요한가요?
Chunk Overlap은 왜 필요한가요?
청크 경계에서 문장이 잘리면 검색 시 관련 내용을 놓칠 수 있습니다. 오버랩을 설정하면 앞뒤 청크가 일부 텍스트를 공유하여 문맥 연결을 유지합니다. 기본값 100은 대부분의 경우 적절합니다.
Bypass Embedding and Retrieval 옵션을 활성화하면 텍스트 분할과 임베딩을 건너뛰고 문서 전체를 LLM 컨텍스트에 직접 주입합니다. 소규모 문서에서만 사용하세요 — 대용량 문서는 토큰 한도를 초과할 수 있습니다.
시맨틱 청킹
신규 기능 — 고정 크기 대신 문장 간 의미 유사도를 기준으로 청크를 분리하는 방식입니다.
테이블 보존
신규 기능 — 문서 내 테이블(HTML/마크다운 형식)을 분리하지 않고 통째로 보존하는 기능입니다.
- 문서에서 테이블(HTML
<table>, 마크다운|...|)을 자동 탐지 - 텍스트 부분만 일반 청킹 수행
- 테이블은 가장 인접한 텍스트 청크에 통째로 붙임
- 청크 크기를 초과하는 대형 테이블은 헤더를 유지하면서 행 단위로 분할
문맥 보존 (Contextual Chunking)
신규 기능 — 각 청크에 전체 문서의 맥락 요약을 LLM이 생성하여 앞에 추가합니다. Anthropic의 Contextual Retrieval 기법을 구현한 기능입니다.
- 청킹 완료 후 각 청크에 대해 LLM 호출
- “이 청크가 전체 문서에서 어떤 위치와 맥락인지” 요약을 생성
- 요약을 청크 앞에 추가하여 벡터화
임베딩 설정
문서를 벡터로 변환하는 임베딩 엔진과 모델을 설정합니다.
지원 엔진:
- SentenceTransformers
- OpenAI
- Azure OpenAI
- Ollama
- Vertex AI
- Gemini
로컬 환경에서 실행되는 오픈소스 임베딩 엔진입니다.
파일 업로드 제한
질의예시 생성 (Question Generation)
문서 청크마다 “사용자가 할 법한 질문”을 LLM이 미리 생성하여 검색 정확도를 높이는 기능입니다.클라우드 스토리지 연동
외부 클라우드 스토리지에서 지식 기반에 문서를 가져올 수 있습니다.- 이 설정은 토글만 제공하며, 실제 인증 정보는 환경 변수로 설정해야 합니다.
환경 변수가 설정되어 있어야 토글을 켤 수 있습니다. 토글을 켜면 지식 기반의 “내용 추가” 메뉴에 해당 클라우드 소스가 표시됩니다.
재인덱싱 및 초기화
아래 작업은 되돌릴 수 없습니다. 실행 전 반드시 확인하세요.
재인덱싱이 필요한 경우
- 임베딩 모델을 변경했을 때
- 검색 엔진(Vector DB)을 변경했을 때
- 청크 크기/오버랩을 변경했을 때
- 문서 처리에 문제가 발생했을 때
관련 페이지
지식 기반
지식 기반 생성 및 문서 관리 — KB별 프로파일 선택
검색 엔진
Vector DB 및 검색 파라미터 설정
동적 필터
지식 기반 메타데이터 필터 설정