- What documents were searched, what tools were invoked, what prompt was sent to the LLM — every step is transparently visible.
Admin > Evaluation > Tracing — search traces by Chat ID or Message ID
Agent answered “I can’t find that information”
trace feature enabled.Tracing Concepts
Processing a single user message involves multiple steps.- Tracing records all these steps in a Trace > Run hierarchy.
Tracing Entry Methods
All three paths lead to the same Evaluation › Tracing screen — buttons ① and ② navigate automatically when clicked, while ③ searches directly by ID.- ① From Conversation Logs (Admin)
- ② Directly from Chat
- ③ Search by ID
Open conversation logs
Select a conversation
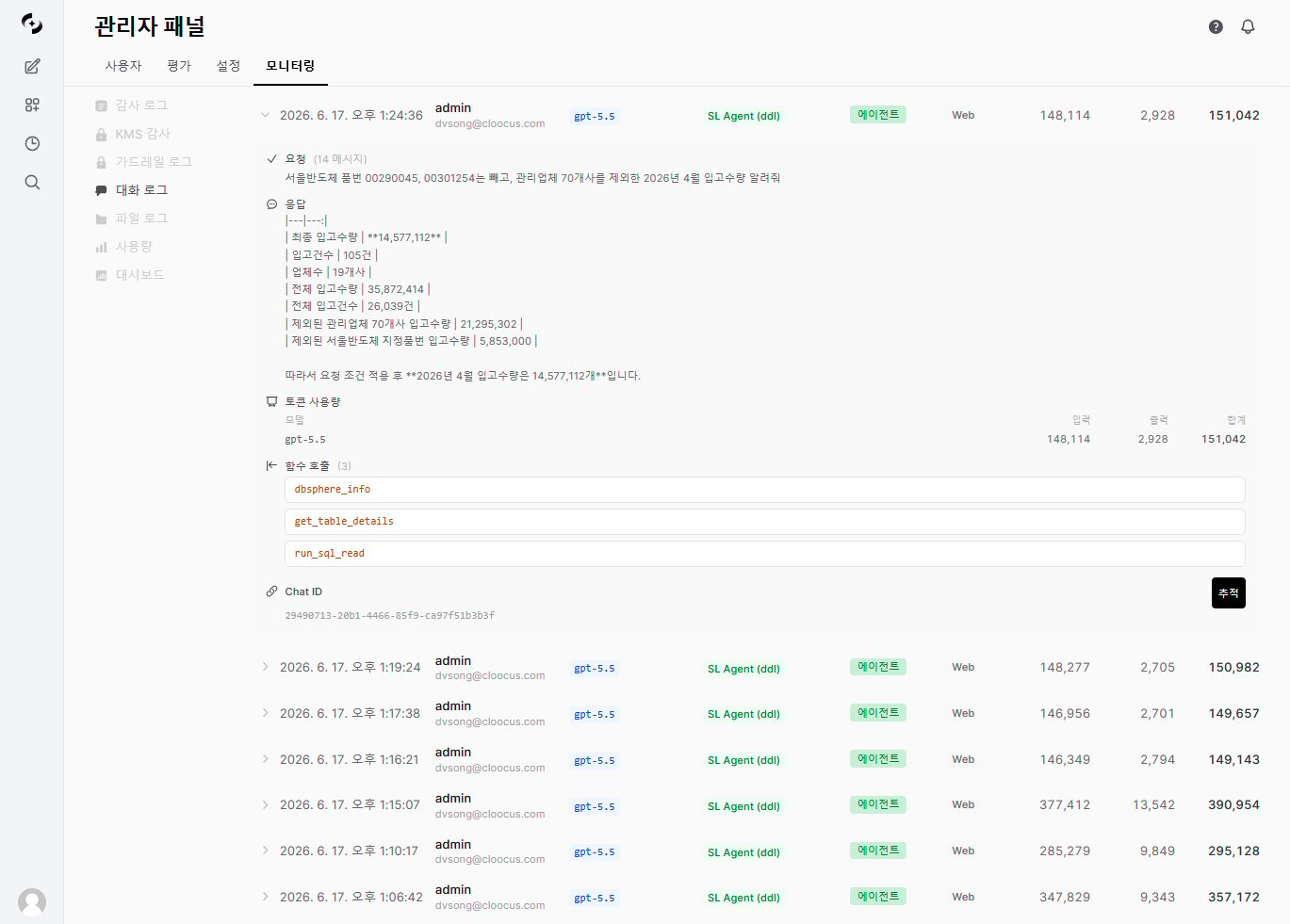
Expanding a conversation shows a 'Trace' button on the right
Arrive at Evaluation › Tracing
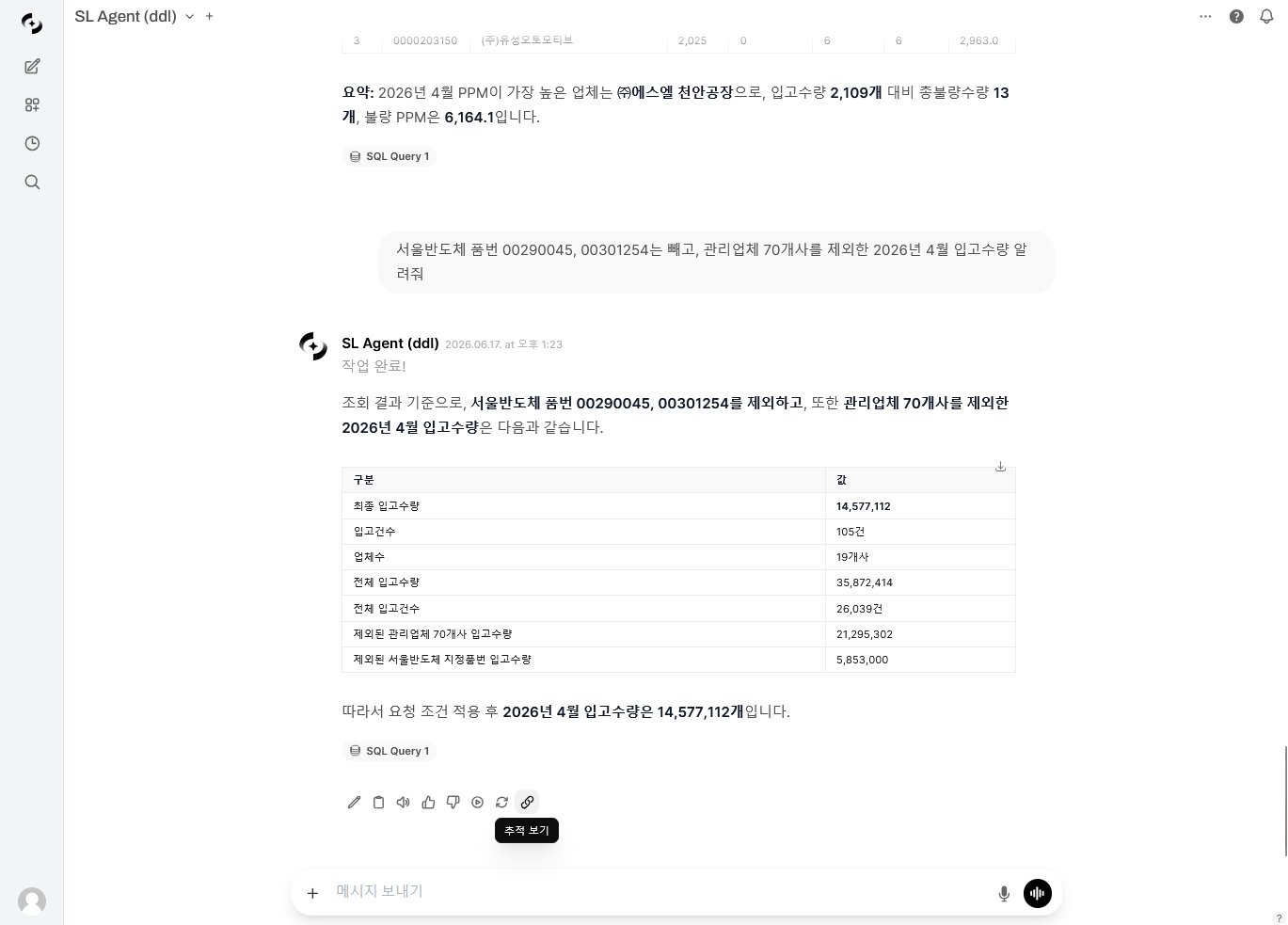

Destination · Evaluation › Tracing
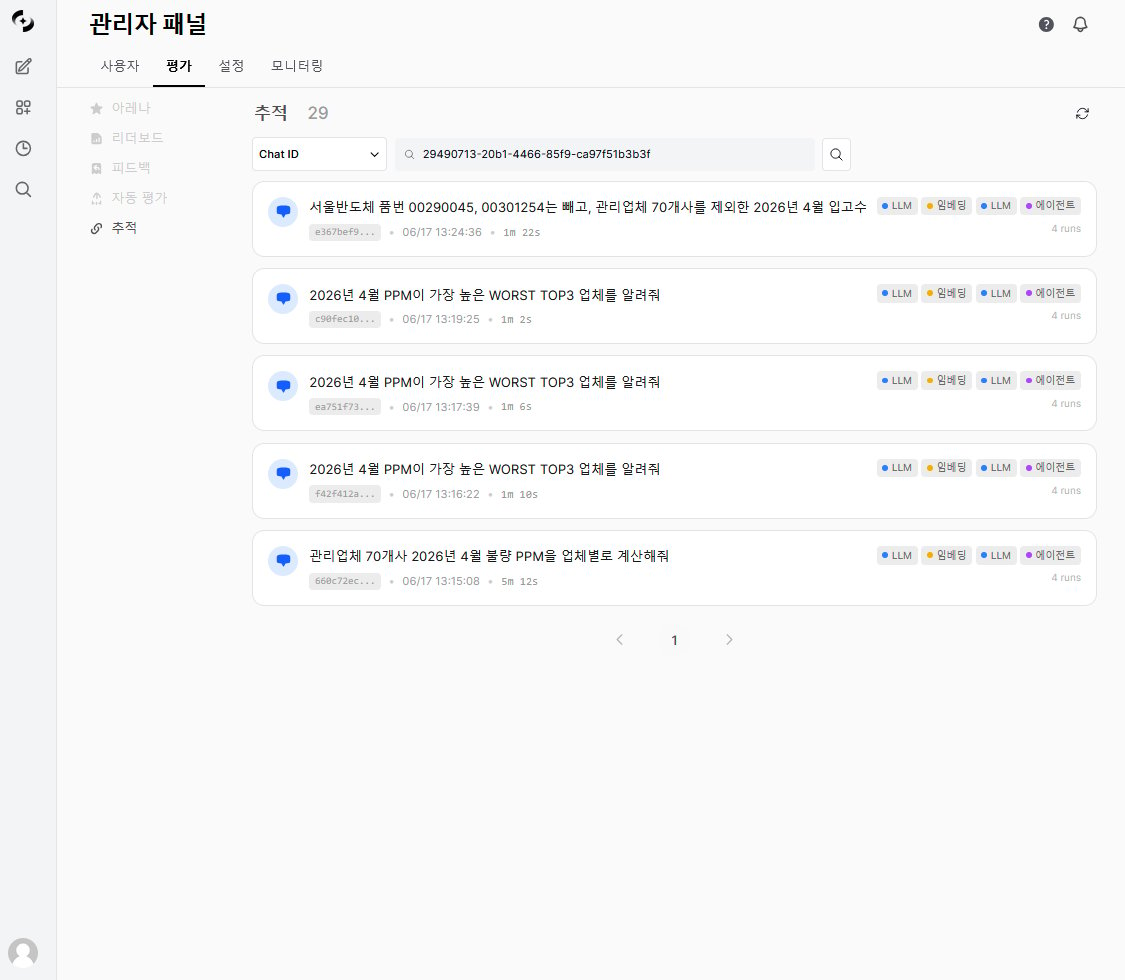
Evaluation › Tracing arrival screen — search list (message cards)
Searching Traces
Searching by Chat ID or Message ID on the Evaluation › Tracing screen produces a list of message cards like the screen above.- Each card is a summary of one user message’s trace, and clicking a card opens the detail view.
Search criteria — Chat ID vs. Message ID
Search criteria — Chat ID vs. Message ID
Message card items
Message card items
How to Read the Trace Detail View
This is the heart of tracing.- Here you see what steps a message went through and what went into and came out of each step.
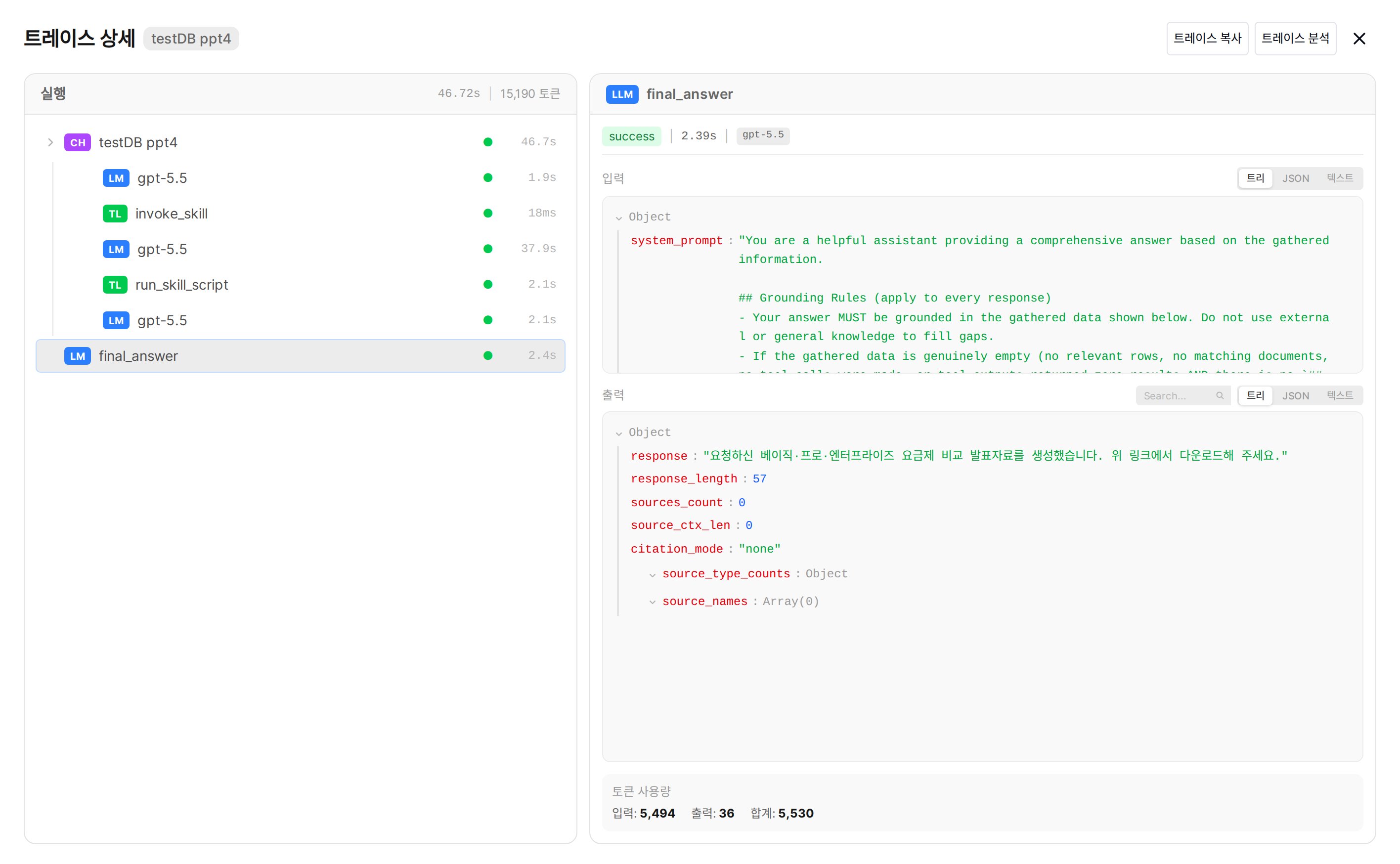
Trace detail — pick a step in the left Run tree and its inputs/outputs appear on the right
CH) repeats LM reasoning and tool calls to gather data, and finally final_answer (LM) writes the answer.
- Left — Run Tree
- Right — Detail Panel
- ● Status — green means OK, red means an error at that step.
- Adjacent time — that step’s latency. The step with the largest value is the bottleneck.
background_tasks trace.All Run types (color legend)
All Run types (color legend)
Agent · LLM · Embed.)Status display (● symbol / color)
Status display (● symbol / color)
Reading in Two Phases
Reading the agent’s response in two phases helps you find the cause quickly.Debugging Points
Agent didn't use a tool (Knowledge Base / DB)?
Agent didn't use a tool (Knowledge Base / DB)?
active_capabilities (tools/features available at that moment) in the Inputs of Phase 1’s LM reasoning Run.- Desired tool not in the list → that feature (Knowledge Base, DB, etc.) isn’t connected to the agent
- Tool present but not called → the model judged low relevance between the question and the tool. Make the tool/feature description more specific
Search ran but the answer is inaccurate?
Search ran but the answer is inaccurate?
sources_count and source_names in the Outputs of the final_answer (LM) Run. (Search results are contained in this output, not in a separate Run.)sources_countis 0 → zero search results. A KB document is missing, or search settings (Top K, Reranker, etc.) need review- Sources exist but the answer is off → check what was passed in the same Run’s Inputs and adjust the answer prompt
Tool execution failed?
Tool execution failed?
Response too slow?
Response too slow?
- LM slow → consider switching to a faster model
- TL/EM slow → check tool/search settings or external services
- GD (guardrail) slow → disable LLM judgment or switch to a faster model
Trace Analysis Report
A feature that analyzes trace data with an LLM to automatically identify the root cause of a problem.Start analysis
Review analysis result
Save/share report
Trace Management
Permissions
Data Cleanup
Old traces are cleaned up via the/api/traces/cleanup developer API.
- Bulk-delete traces before a specific timestamp (in milliseconds, ms).
Use Cases
Response Quality Debugging
Response Quality Debugging
- Click the View Tracing button on a chat message
- Select the
final_answer(LM) step in the left Run tree - In Outputs, check
sources_count·source_namesto see whether search results were reflected - In Inputs, check what was passed to the model
- Generate a Trace Analysis Report to auto-identify the root cause
Latency Analysis
Latency Analysis
- Open the trace of a slow response
- Compare the latency next to each step in the Run tree
- Identify the longest step (e.g., tool 0.8s, LLM 3.2s)
- Optimize that step (adjust search settings, change the model, etc.)
Tool Execution Error Tracking
Tool Execution Error Tracking
- Open the suspected trace
- Select the TL (Tool) Run marked with a red ●
- Check the error content in Outputs
- Verify the passed parameters in Inputs
Token Usage Analysis
Token Usage Analysis
- Check overall trace usage via total tokens at the top of the detail view
- Compare per-LM Run Token Usage (Input/Output/Total) in the Run tree
- Check the token ratio of Phase 1 (agent run) vs. Phase 2 (
final_answer) - Identify unnecessarily large prompts or repeated calls
FAQ
Is tracing recorded automatically?
Is tracing recorded automatically?
How long is trace data retained?
How long is trace data retained?
Does tracing affect response speed?
Does tracing affect response speed?
Do analysis reports also consume tokens?
Do analysis reports also consume tokens?
trace_analysis. Analysis only runs when manually triggered.